dbt-data-diff¶
![]()
Data-diff solution for dbt-ers with Snowflake ❄️ 🌟
Who is this for?
- Primarily for people who want to perform Data-diff validation on the Blue-Green deployment 🚀
- Other good considerations 👍
- UAT validation: data-diff with PROD
- Code-Refactoring validation: data diff between old vs new
- Migration to Snowflake: data diff between old vs new (requires to land the old data to Snowflake)
- CI: future consideration only ⚠️
Core Concept 🌟¶
dbt-data-diff package provides the diff results into 3 categories or 3 levels of the diff as follows:
- 🥉 Key diff (models): Compare the Primary Key (
pk) only - 🥈 Schema diff (models): Compare the list of column's Names and Data Types
- 🥇 Content diff (aka Data diff) (models): Compare all cell values. The columns will be filtered by each table's configuration (
include_columnsandexclude_columns), and the data can be also filtered by thewhereconfig. Behind the scenes, this operation does not require the Primary Key (PK) config, it will perform Bulk Operation (INTERCEPTorMINUS) and make an aggregation to make up the column level's match percentage
Sample diffing: 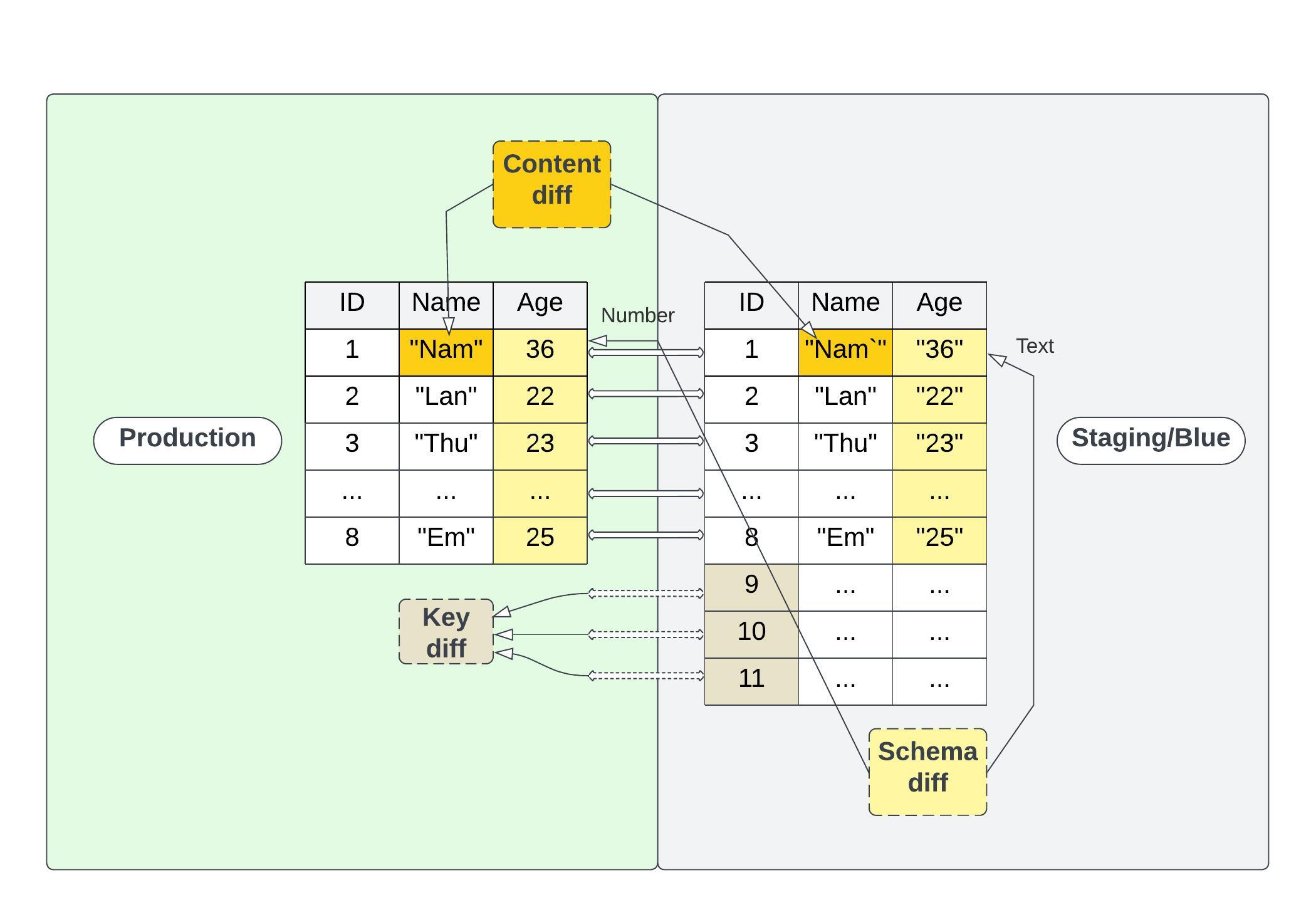
Behind the scenes, this package leverages the ❄️ Scripting Stored Procedure which provides the 3 ones correspondingly with 3 categories as above. Moreover, it utilizes the DAG of Tasks to optimize the speed with the parallelism once enabled by configuration 🚀
Sample DAG:
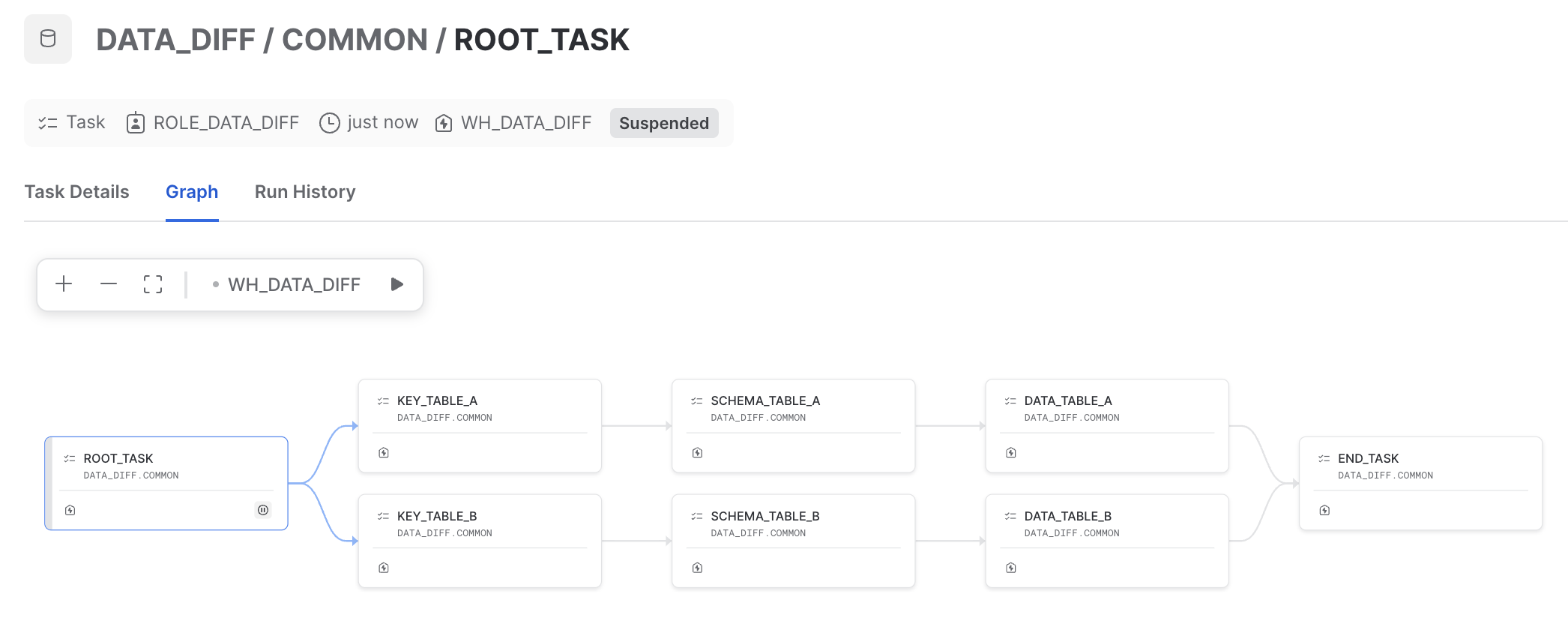
Installation¶
- Add to
packages.ymlfile:
Or use the latest version from git:
- (Optional) Configure database & schema in
dbt_project.ymlfile:
vars:
# (optional) default to `target.database` if not specified
data_diff__database: COMMON
# (optional) default to `target.schema` if not specified
data_diff__schema: DATA_DIFF
- Create/Migrate the
data-diff's DDL resources
Quick Start¶
1. Configure the tables that need comparing in dbt_project.yml¶
We're going to use the data_diff__configured_tables variable (Check out the dbt_project.yml/vars section for more details!)
For example, we want to compare table_x between PROD db and DEV one:
vars:
data_diff__configured_tables:
- src_db: your_prod
src_schema: your_schema
src_table: table_x
trg_db: your_dev
trg_schema: your_schema
trg_table: table_x
pk: key # multiple columns splitted by comma
include_columns: [] # [] to include all
exclude_columns: ["loaded_at"] # [] to exclude loaded_at field
2. Refresh the configured tables's data¶
We can skip this step if you already did it. If not, let's run the below command:
dbt run -s data_diff \
--full-refresh \
--vars '{data_diff__on_migration: true, data_diff__on_migration_data: true, data_diff__full_refresh: true}'
In the above:
--full-refreshanddata_diff__full_refresh: To re-create all data-diff modelsdata_diff__on_migration: true: To re-create the stored proceduresdata_diff__on_migration_data: true: To reset the configured data
3. Trigger the validation via dbt operation¶
Now, let's start the diff run:
dbt run-operation data_diff__run # normal mode, run in sequence, wait unitl finished
# OR
dbt run-operation data_diff__run_async # async mode, parallel, no waiting
dbt run-operation data_diff__run_async --args '{is_polling_status: true}'
# async mode, parallel, status polling
In the Async Mode
We leverage the DAG of tasks, therefore the dbt's ROLE will need granting the addtional privilege:
📖 Or via dbt hook by default (it will run an incremental load for all models)
# Add into dbt_project.yml file
# normal mode
on-run-end
- > # run data-diff hook
{% if var("data_diff__on_run_hook", false) %}
{{ data_diff.data_diff__run(in_hook=true) }}
{% endif %}
# async mode
on-run-end
- > # run data-diff hook
{% if var("data_diff__on_run_hook", false) %}
{{ data_diff.data_diff__run_async(in_hook=true) }}
{% endif %}
4. [Bonus] Deploy the helper 🤩¶
Our helper is the Streamlit in Snowflake (SiS) application which was built on the last diff result in order to help us to have a better examining with the actual result without typing SQL.
Let's deploy the Streamlit app by running the dbt command as follows:
Sample logs
02:44:50 Running with dbt=1.7.4
02:44:52 Registered adapter: snowflake=1.7.1
02:44:53 Found 16 models, 2 operations, 21 tests, 0 sources, 0 exposures, 0 metrics, 558 macros, 0 groups, 0 semantic models
02:44:53 [RUN]: sis_deploy__diff_helper
02:44:53 query:
create schema if not exists data_diff.blue_dat_common;
create or replace stage data_diff.blue_dat_common.stage_diff_helper
directory = ( enable = true )
comment = 'Named stage for diff helper SiS appilication';
PUT file://dbt_packages/data_diff/macros/sis/diff_helper.py @data_diff.blue_dat_common.stage_diff_helper overwrite=true auto_compress=false;
create or replace streamlit data_diff.blue_dat_common.data_diff_helper
root_location = '@data_diff.blue_dat_common.stage_diff_helper'
main_file = '/diff_helper.py'
query_warehouse = wh_data_diff
comment = 'Streamlit app for the dbt-data-diff package';
02:45:02 <agate.MappedSequence: (<agate.Row: ('Streamlit DATA_DIFF_HELPER successfully created.')>)>
Once it's done, you could access to the app via: Steamlit menu / DATA_DIFF_HELPER or via this quick link:
👉 Check out the sample app UI
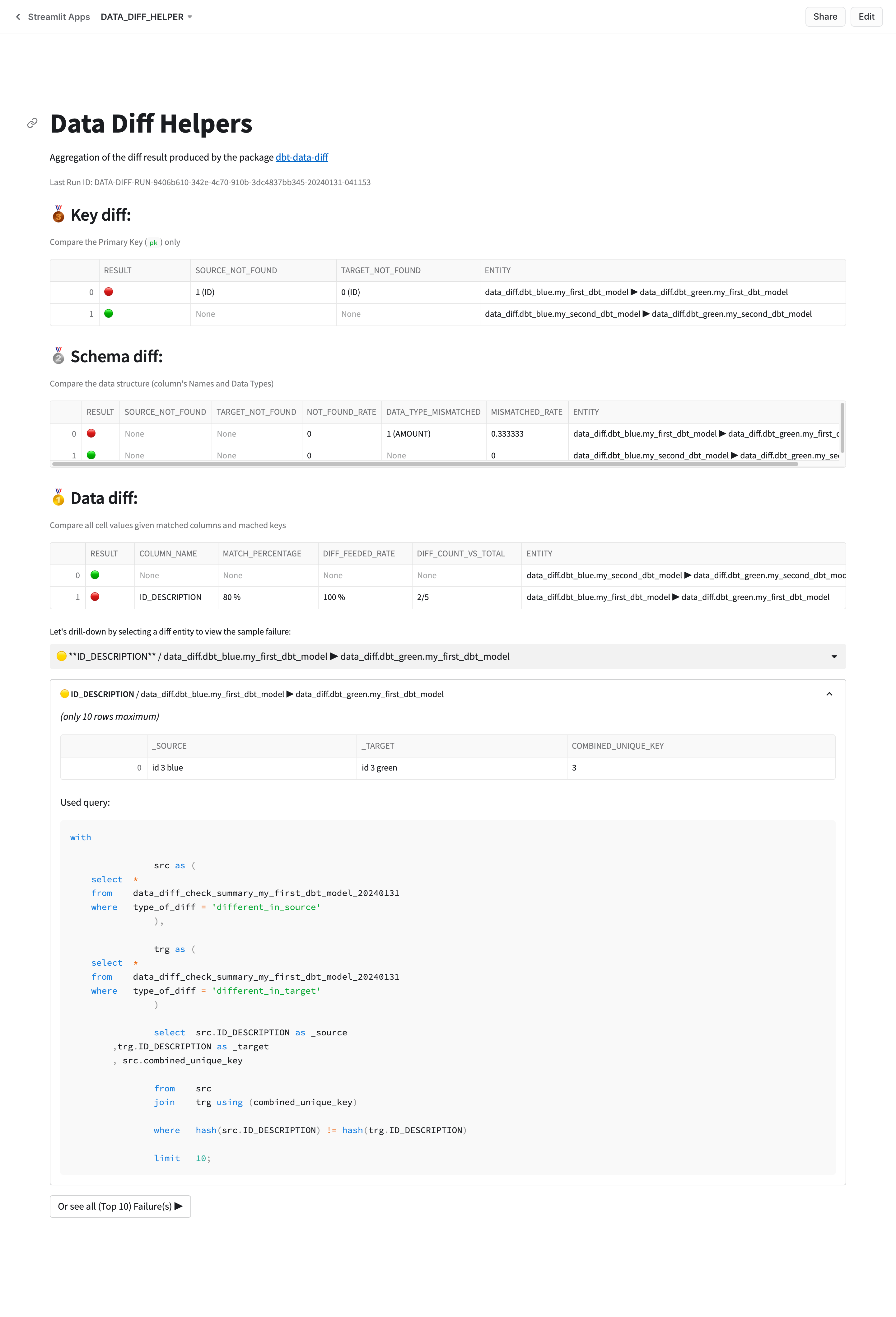
Demo¶
Part 1: Configure and prepare Blue/Green

Part 2: Run data diff & examine the result

Variables¶
See dbt_project.yml file
Go to vars section here 🏃
We managed to provide the inline comments only for now, soon to have the dedicated page for more detail explanation.
Here are the full list of built-in variables:
data_diff__databasedata_diff__schemadata_diff__on_migrationdata_diff__on_migration_datadata_diff__on_run_hookdata_diff__full_refreshdata_diff__configured_tables__source_fixed_namingdata_diff__configured_tables__target_fixed_namingdata_diff__configured_tablesdata_diff__auto_pipe
How to Contribute ❤️¶
dbt-data-diff is an open-source dbt package. Whether you are a seasoned open-source contributor or a first-time committer, we welcome and encourage you to contribute code, documentation, ideas, or problem statements to this project.
👉 See CONTRIBUTING guideline for more details or check out CONTRIBUTING.md
🌟 And then, kudos to our beloved Contributors:
⭐ Special Credits to 👱 Attila Berecz who is the OG Contributor of the Core Concept and all the Snowflake Stored Procedures
Features comparison to the alternative packages¶
| Feature | Supported Package | Notes |
|---|---|---|
| Key diff |
| ✅ all available |
| Schema diff |
| (*): Only available in the paid-version 💰 |
| Content diff |
| (*): Only available in the paid-version 💰 |
| Yaml Configuration |
| data_diff will use the toml file, dbt_audit_helper will require to create new models for each comparison |
| Query & Execution log |
| Except for dbt's log, this package to be very transparent on which diff queries executed which are exposed in log_for_validation model |
| Snowflake-native Stored Proc |
| Purely built as Snowflake SQL native stored procedures |
| Parallelism |
| dbt_data_diff leverages Snowflake Task DAG, the others use python threading |
| Asynchronous |
| Trigger run & go away. Decide to continously poll the run status and waiting until finished if needed |
| Multi-warehouse supported |
| (*): Future Consideration 🏃 |
About Infinite Lambda¶
Infinite Lambda is a cloud and data consultancy. We build strategies, help organizations implement them, and pass on the expertise to look after the infrastructure.
We are an Elite Snowflake Partner, a Platinum dbt Partner, and a two-time Fivetran Innovation Partner of the Year for EMEA.
Naturally, we love exploring innovative solutions and sharing knowledge, so go ahead and:
🔧 Take a look around our Git
✏️ Browse our tech blog
We are also chatty, so:
👀 Follow us on LinkedIn
👋🏼 Or just get in touch
